This post was originally written for the Black Pepper Software blog. The original was posted on 12/09/2013.
It is very common requirement for software systems to generate a PDF document of some kind. For instance, at Black Pepper, we’ve built a number of e-commerce systems, and usually our clients have a requirement to produce a nicely formatted invoice or contract which their customers can access through the web.
We often work on a Java stack, and there are therefore a number of approaches to generating a PDF, including Apache FOP (based on XSL), iText, and a variety of others [1]. In a number of solutions we’ve gone down the iText approach since it’s pure Java and therefore reasonably straight forward to integrate and test. However, it presents a DOM-based approach which is not without it shortcomings. A better solution is to use a template so that layout can be separated from the PDF generation. That’s precisely what we wanted to do for a recent project, when we discovered the XDocReport library [2] which provided exactly what we needed. This post describes how to get started with that library.
The problem
In previous projects, we often used the iText library to produce a PDF, writing quite low-level code to describe the Document Object Model (DOM) of the PDF. Something like the following snippiet:
1 2 3 4 5 6 7 8 9 | |
However, following this approach results in a fairly tight-coupling between how a PDF is produced and how it looked. Every time our clients wanted to change the formatting of their report, we had to change our code. In terms of the Model-View-Controller pattern, it felt that we didn’t have the correct separation between our controller and view logic. What we needed was a way of templating a PDF document and then substituting our data into placeholders.
Of course, templating is not new to us. We commonly leverage view templates when we generate emails, reports, and other HTML-based documents. One of our favourite template technologies is Apache Velocity — an open-source template engine that has become the de-facto standard templating engine in many enterprise Java projects. Ideally, we wanted to be able to use Velocity to produce our PDF.
The solution – XDocReport
The XDocReport library [2] is a fantastic utility that provided exactly what we needed. It builds on top of Apache Velocity and IText, but instead of directly producing PDFs, it separates the problem into two parts: a ‘mail-merge’ of a template document, followed by a reliable converter that produces a PDF from the merged document. Templates can be based on either the popular Microsoft .docx format, or alternatively, the OpenOffice .odt format.
What’s really great about XDocReport is the way it plays nicely with the formats it’s templating for. Both the Microsoft and OpenOffice format have built-in support for adding data-driven fields which are commonly used when performing a traditional mail merge. To it’s credit, XDocReport utilises these features to capture the template placeholders. As a result, it requires very little (if any) software engineering skills to update and maintain a template.
Using XDocReport
In order to get going we had to add the library’s dependencies to our project. Initially it was a bit tricky to track down the exact dependencies because a number of the dependent libraries have been repackaged (presumably to help when deploying into an OSGI context). If you’re using Maven (or Ivy, Gradle etc), then you can grab the jars from the Maven Central repository using the following definitions:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Next we needed to create a template and add it to our classpath. We decided to use odt as our template format. Marking up the document is done using the ‘add field’ menu in OpenOffice or LibreOffice writer [3]. Inside the template fields you can add artbitrary Velocity expressions. We made use of #if…#end directives because we were generating a contract that only needed to include a VAT number if a customer was VAT registered.
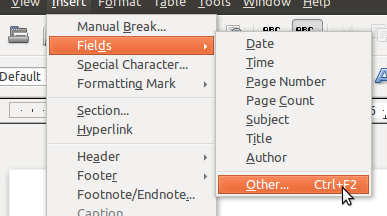

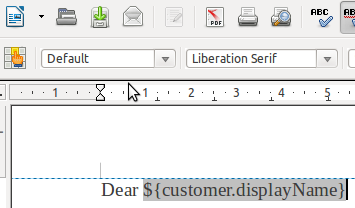
Next we needed some code to populate values into our template. First we created a simple object to represent our model
public class Invoice {
private String formattedTotal;
private String vatNumber;
private boolean vatRegistered;
...
}
Then, finally, we needed some glue code to generate a PDF (here with no exception handling or IO cleanup)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Integrating within Spring MVC
In practice we want to generate and serve the PDF over HTTP. We were using Spring MVC to manage both our server-side pages and RESTful APIs so it made sense to enapsulate our PDF generaton into a custom view. Creating a PDF document on the fly then was a simple matter of writing a small amount of controller logic, passing in a model object and a reference to the template we wanted to use.
Conclusion
Using XDocReport has enabled us to produce nicely formatted PDF documents based on data inside our application. The advantage over alternative approaches we’ve followed in the past is that anyone with basic word processor skills can update the templates without requiring a software engineer to write code. Using a template-based approach also allowed us to deliver the functionality much faster, and when our customer required a different template to be used in certain situations, dynamically switching the template was a really simple code change.
References
[1] List of PDF libraries for Java: [http://java-source.net/open-source/pdf-libraries/itext]
[2] The XDocReport library: [http://code.google.com/p/xdocreport]